

Giải mã quá trình crawl website trong SEO là điều vô cùng quan trọng. Vậy chính xác thì crawl website là gì và hoạt động như thế nào? Cùng tìm hiểu để hiểu rõ hơn về vai trò của nó trong việc tối ưu hóa website và nâng cao thứ hạng trên công cụ tìm kiếm.
[Từ A-Z] Crawl website là gì?
Crawl là gì?
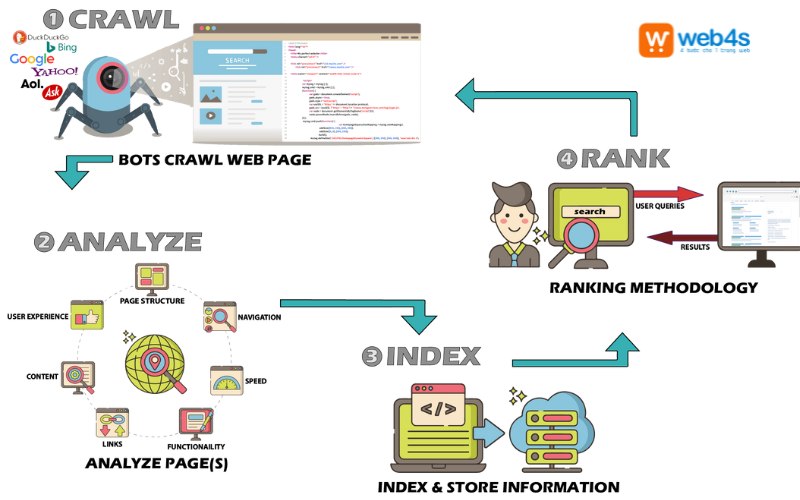
Crawl trong SEO, thường được hiểu là quá trình thu thập dữ liệu hoặc lục lọi website. Hiểu đơn giản, bạn hãy nghĩ đến một con nhện đang bò khắp một trang web, đi từ đường link này sang đường link khác để tìm kiếm thông tin. Con nhện này chính là bot (hay còn gọi là crawler hoặc spider) của các công cụ tìm kiếm như Google, Bing.

Ứng dụng & vai trò của crawl trong SEO
Crawl là một quá trình nền tảng trong SEO, đóng vai trò quan trọng trong việc giúp các công cụ tìm kiếm khám phá và hiểu rõ nội dung của website.
- Khám phá website: Giúp các công cụ tìm kiếm biết đến sự tồn tại của website bạn.
- Xếp hạng: Dựa vào thông tin thu thập được, các công cụ tìm kiếm sẽ đánh giá và xếp hạng website của bạn trên kết quả tìm kiếm.
- Cập nhật nội dung: Khi bạn cập nhật nội dung mới, bot sẽ quay lại để thu thập và cập nhật thông tin trong chỉ mục.
XEM THÊM: 5 xu hướng SEO mới nhất giúp SEOer vươn lên Top Google
Bí mật hoạt động của bot crawl dữ liệu trên website bạn
Bot công cụ tìm kiếm hoạt động chủ yếu thông qua quá trình thu thập và lập chỉ mục thông tin khi crawl dữ liệu website. Quá trình này diễn ra một cách đơn giản, bắt đầu bằng việc bot duyệt qua danh sách các URL đã được chỉ định.
- Duyệt danh sách URL: Bot sẽ khởi động bằng cách truy cập vào các URL có sẵn trong danh sách, tiến hành thu thập dữ liệu từ những trang này.
- Khám phá liên kết mới: Trong quá trình thu thập, bot sẽ tìm kiếm các liên kết đến các URL mới, từ đó mở rộng danh sách những trang cần được crawl.
- Tiến hành crawl liên tục: Bot sẽ tiếp tục quá trình crawl dữ liệu qua các URL liên quan, tạo thành một chuỗi thông tin liên kết.
Ngoài ra, bot cũng ưu tiên việc crawl dựa trên nhiều yếu tố như lượng backlink, lượng traffic và tầm quan trọng của nội dung. Các trang web có thông số cao thường được xem là nguồn thông tin chất lượng và có uy tín, do đó sẽ được ưu tiên trong quá trình thu thập dữ liệu.
Thêm vào đó, bot công cụ tìm kiếm còn tuân thủ một số chính sách liên quan đến tần suất và thứ tự thu thập dữ liệu. Điều này giúp đảm bảo rằng những trang quan trọng và có cập nhật mới được crawl thường xuyên hơn, từ đó cải thiện khả năng cung cấp kết quả tìm kiếm chính xác và kịp thời cho người dùng.
XEM THÊM: SEO Checklist 2024: Hướng Dẫn Chi Tiết Để Tối Ưu Hóa Website
Cách chặn Google crawling dữ liệu thừa trên website của bạn
Nếu bạn muốn ngăn Google crawling những dữ liệu không mong muốn trên website của mình, hãy cùng khám phá ba phương pháp phổ biến để cải thiện hiệu quả SEO thông qua việc chặn Google thu thập thông tin không cần thiết.
Sử dụng file Robots.txt
Tệp Robots.txt nằm ở thư mục gốc của website và chứa các chỉ thị hướng dẫn bot công cụ tìm kiếm về những phần nào trên trang web nên hoặc không nên thu thập dữ liệu. Việc này giúp bảo vệ thông tin nhạy cảm và tối ưu hóa hiệu suất crawl.
File Robots.txt cũng cho phép bạn điều chỉnh tốc độ thu thập dữ liệu, giúp giảm tải cho máy chủ và nâng cao hiệu suất trang web. Khi Googlebot phát hiện tệp này, nó sẽ tuân thủ các chỉ dẫn để thu thập dữ liệu một cách hợp lý, đảm bảo rằng các trang quan trọng được lập chỉ mục và xếp hạng tốt trong kết quả tìm kiếm.
Tối ưu hóa Crawl Budget
Crawl Budget đề cập đến số lượng URL mà Googlebot có thể thu thập trước khi dừng lại. Để tối ưu hóa quá trình này, bạn cần lưu ý những điểm sau:
- Đảm bảo Googlebot không quét các trang không quan trọng hoặc trùng lặp, để tập trung vào các nội dung chất lượng và duy nhất.
- Sử dụng file Robots.txt để chỉ định các phần không cần thiết mà Googlebot không nên truy cập.
- Cân nhắc sử dụng các chỉ thị như thẻ “Canonical” hoặc “Noindex” để hướng dẫn Googlebot xử lý các trang một cách chính xác, giúp tránh các vấn đề về nội dung trùng lặp.
Tận dụng tính năng tham số URL trong Google Search Console
Tham số URL là những đoạn mã bổ sung vào URL chính để phân biệt các phiên bản khác nhau của cùng một nội dung trang web. Ví dụ, khi bạn mua sắm trên một trang thương mại điện tử, các tham số có thể được sử dụng để lọc sản phẩm theo giá, màu sắc hoặc kích cỡ.
Tính năng tham số URL trong Google Search Console cho phép bạn chỉ định cho Googlebot biết cách xử lý các tham số này, quyết định lập chỉ mục hoặc bỏ qua chúng. Điều này giúp ngăn chặn Googlebot crawl dữ liệu các trang trùng lặp, giữ cho chỉ mục của bạn luôn sạch sẽ và hiệu quả.

XEM THÊM: 5+ Cách SEO hình ảnh lên Top Google Hiệu quả nhất
Web crawler hoạt động như thế nào?
Web crawler (hay còn gọi là bot, spider) là những chương trình máy tính được thiết kế để tự động duyệt web, thu thập thông tin từ các trang web và lập chỉ mục để các công cụ tìm kiếm có thể hiển thị kết quả tìm kiếm cho người dùng.
Quá trình hoạt động của một web crawler thường diễn ra như sau:
- Bắt đầu từ một URL: Crawler bắt đầu từ một URL khởi điểm, có thể là một trang web ngẫu nhiên hoặc một danh sách các URL được cung cấp.
- Phân tích HTML: Crawler tải trang web về và phân tích mã HTML để trích xuất các liên kết đến các trang khác.
- Theo dõi các liên kết: Crawler sẽ theo các liên kết này để truy cập vào các trang mới và lặp lại quá trình phân tích HTML.
- Lập chỉ mục: Thông tin thu thập được từ các trang web, bao gồm tiêu đề, mô tả, từ khóa, và các liên kết khác, sẽ được lưu trữ vào một cơ sở dữ liệu lớn gọi là chỉ mục.
- Cập nhật chỉ mục: Crawler sẽ định kỳ quay lại các trang web đã thu thập để kiểm tra xem có cập nhật nội dung mới không và cập nhật chỉ mục.
Khám phá bot crawl của những công cụ tìm kiếm hàng đầu
Để thu thập dữ liệu một cách hiệu quả, các công cụ tìm kiếm đóng vai trò quan trọng. Hãy cùng khám phá bot crawl của những công cụ tìm kiếm phổ biến hiện nay, giúp bạn tối ưu hóa quy trình SEO của mình nhanh chóng hơn.
Googlebot của Google
Googlebot là một trong những bot crawl dữ liệu nổi tiếng nhất hiện nay. Được phát triển bởi Google, Googlebot là công cụ quan trọng trong việc thu thập và cập nhật thông tin từ các trang web, giúp chúng xuất hiện trong kết quả tìm kiếm. Bạn có thể tận dụng Googlebot để cải thiện chiến dịch SEO của mình thông qua các cách sau:
- Sử dụng thông tin mà Googlebot thu thập, như tiêu đề, nội dung, liên kết và các yếu tố khác, để kiểm tra và tối ưu hóa trang web, từ đó nâng cao thứ hạng trên kết quả tìm kiếm.
- Theo dõi những thay đổi trên trang web nhờ Googlebot để thực hiện các điều chỉnh cần thiết, giúp duy trì và cải thiện vị trí của trang web.
Bingbot của Bing
Bingbot là một thành phần quan trọng trong hệ thống tìm kiếm của Bing, chịu trách nhiệm thu thập và cập nhật dữ liệu từ các trang web trên Internet. Các chức năng chính của Bingbot bao gồm:
- Thu thập dữ liệu: Bingbot tự động lấy thông tin từ các trang web bằng cách theo dõi các liên kết, thu thập các yếu tố như tiêu đề, nội dung và liên kết để lưu trữ vào cơ sở dữ liệu của Bing.
- Cập nhật dữ liệu: Bingbot thường xuyên quét lại các trang đã thu thập để đảm bảo thông tin được cập nhật và chính xác, đồng thời theo dõi các thay đổi để cập nhật cơ sở dữ liệu.
- Xếp hạng trang web: Bingbot đánh giá nội dung, độ tin cậy và tối ưu hóa SEO của trang web để xác định thứ hạng trong kết quả tìm kiếm của Bing, giúp cải thiện hiệu suất và sự hiển thị của trang web.
Yandexbot của Yandex
Yandexbot là một phần quan trọng trong hệ thống tìm kiếm của Yandex, với các nhiệm vụ tương tự như Bingbot và Googlebot, bao gồm:
- Crawl dữ liệu: Yandexbot thu thập thông tin bằng cách theo dõi các liên kết trên trang web, thu thập tiêu đề, nội dung và các yếu tố khác.
- Lưu trữ và cập nhật dữ liệu: Yandexbot định kỳ quét lại các trang đã thu thập để đảm bảo thông tin luôn được cập nhật và chính xác.
- Đánh giá và xác định thứ hạng: Yandexbot đánh giá các trang web dựa trên tiêu chí như nội dung, độ tin cậy và sự tối ưu hóa SEO, từ đó xác định vị trí trên kết quả tìm kiếm của Yandex.
XEM THÊM: Viết Content chuẩn SEO lên TOP [Chỉ với 5 bước]
Lời kết
Crawl website trong SEO là một quy trình thiết yếu giúp các công cụ tìm kiếm thu thập và lập chỉ mục thông tin từ các trang web. Hiểu rõ cách thức hoạt động của bot crawl và các yếu tố ảnh hưởng đến quá trình này sẽ giúp bạn tối ưu hóa trang web hiệu quả hơn. Bằng cách điều chỉnh và cải thiện nội dung cũng như cấu trúc của website, bạn có thể nâng cao khả năng hiển thị trong kết quả tìm kiếm, từ đó gia tăng lưu lượng truy cập và đạt được mục tiêu kinh doanh của mình.
Nếu còn thắc mắc gì, hãy liên hệ Web4s để được hỗ trợ thêm thông tin ngay nhé!
- Tổng đài hỗ trợ (24/7): 1900 6680 hoặc 0901191616
- Email: contact@sm4s.vn
- Website: https://deals.com.vn/
- Fanpage: https://www.facebook.com/web4s
- YouTube: https://www.youtube.com/channel/UCr778Hq-QhCEBTGFc9n-Pcg

